Measure Twice: Exploring the Evaluation of Agentic Security Detection Systems

Originally published on LinkedIn.
On applying scientific skepticism and rigor to the measurement of agentic security systems.
edit: forgot a source!
Photo by ClickerHappy: https://www.pexels.com/photo/wood-tool-saw-9280/
tl;dr
Is applying LLMs to detection & response a good idea? No clue. But defining the systems of measurement to determine if it’s a good idea or not, very much so -is- a good idea. I wrote a proof of concept to explore what that measurement system might look like. The PoC is available in this repository.
Intro
I’m concerned, dear reader.
My industry is changing by the hour. The velocity of change in cybersecurity has always been high, but the current wave of AI adoption feels different. Most concerning to me as a researcher for a security product is that security vendors in the space are applying agentic workflows to detection and response systems, promising that they can completely obviate the need for human decision making.
That is an extraordinary claim. Extraordinary claims require extraordinary evidence.
Historically, detection engineering has been grounded in determinism. A detection rule fires when specific conditions are met. A signal either matches a pattern or it does not. Sure, we argue about thresholds, coverage, false positive rate, efficacy, and everything in between, but the logic is transparent and reproducible.
Agentic systems change that equation. Agentic detection systems assert that an AI agent can ultimately produce a determination of malice when faced with a security relevant events and do so as well, if not better, than a trained human. The promise is adaptive security at the agentic scale. The cost (besides the electricity and token consumption) is predictability. And if we’re going to make that trade, maybe we need to know what we’re getting ourselves into first.
So I’m concerned. But I ain’t stressin’. (True friends, one question?). I generally don’t like operating in the fear zone, so despite having a bad feeling about the whole ordeal, I’ve always found that nothing kills fear faster than forging ahead towards understanding. So come along with me to better understand the problem space of applying agentic AI to detection and response.
Background
I’m a security practitioner and red teamer by trade. Red teaming is, in essence, about thoroughly testing assumptions about an organization’s security posture, often to the point of breaking it wide open. Today, I perform research in the realm of identity detection & response, specifically in Azure/M365. My current responsibilities include leading the innovation and efficacy of an ITDR product that protects a customer base as large and diverse as New York City from identity attacks.
These three roles (driving innovation, measuring efficacy, and testing assumptions vigorously) have led me to value applying scientific rigor in all aspects of the security domain. Too often, cybersecurity assumes too much. This is why the subject is so pressing to me. The gleam of a flashy new technology might dazzle at first, but we have to remain focused on what tangible security outcomes may or may not happen if we launch headfirst into widespread adoption in the security realm. Right now, I see my industry assuming that probabilistic detection systems will work out at scale. Will they?
Determining the Probabilistic
From my work in ITDR research, I’ve learned three things: I like my eggs over easy, my milkshakes thiccc (with three c’s) and my detection systems deterministic.
If you can’t boil your detection logic down to a clean set of “if, then” statements, you have a detection observability problem. If you have a detection observability problem, you won’t know the exact levers to turn when one detection case succeeded in finding a true positive while an identical case failed. If that happens and you work at the New York City scale, you’re cooked.
Agentic security, therefore, seems like a non-starter. Agentic systems, particularly large language models, are probabilistic by nature. Simple cases may be effectively deterministic, where prompting “the sky is” will predictably produce “blue” (or maybe more accurate these days, “falling”), but there are a colossal amount of assumptions that go into trusting LLM output in more complicated cases like detection and response in the cloud space. I recently watched an excellent presentation on this subject by Yigael Berger that unraveled some of the challenges. One point in particular stuck with me: Berger argues that cloud audit logs are really more “cloudish” than “English.” LLMs, on the other hand, are largely trained on English corpora. Expecting a language model trained on internet text to interpret the semantic nuance of Azure sign-in telemetry is optimistic. And the language of the training material only scratches the surface of the issues with applying this technology to identifying evil in motion. These systems are, fundamentally, unpredictable at the cloud log scale.
So is that it, then? Is there even any way forward? In that same presentation linked above, Berger asserts that yes, there is practical application for LLMs in the detection and response space. Not without challenges, certainly, but a path forward exists.
And that got me thinking. I’ve been skeptical of AI’s applications to -checks notes- every damn thing under the sun lately, especially in the area of detection and response. At the outset, it seems like a complete non-starter to try to use probabilistic systems to detect cyber threats. But does that mean my skepticism and my prior beliefs are correct? Does this subject not warrant the same scientific rigor we apply to every other detection system?
It no longer serves us to bury our heads in the sand and refuse to engage with the question of whether LLMs should be applied to threat detection. Like it or not, that genie is out of the bottle now. What we can do is choose how we apply scientific rigor and skepticism to the process of evaluating how these models perform. If agentic systems perform worse than traditional detection logic, that should emerge in the data. If they perform better, that should also emerge in the data. Either way, the data should decide.
This blog details my exploration of answering the question: how can we evaluate the performance of agentic threat detection systems? How do we build the harness?
Theory: The Agentic Security Detection Paradigm
Traditional detection systems are deterministic pipelines. They evaluate telemetry against explicit rules. If you’re familiar with the Sigma detection engine syntax, detection logic can effectively be boiled down to a ladder-logic set of criteria:
title: High Volume Failed Azure AD Sign-ins from Single IP
id: a1b2c3d4-e5f6-7890-abcd-ef1234567890
status: experimental
description: Detects an unusual volume of failed sign-in attempts from a single IP address, which may indicate brute force or credential stuffing activity.
author: Some Cool-ass Detection Engineer
date: 2025/03/14
logsource:
product: azure
service: signin
detection:
selection:
ResultType: 50126 # Invalid username or password
condition: selection | count() by IPAddress > 10
falsepositives:
- Legitimate users repeatedly mistyping passwords
- Service accounts with expired credentials
level: mediumThe system makes detection logic transparent, accessible, and readable. If a detection fires incorrectly, we inspect the rule and adjust it. This works extremely well at scale because flat logic like this requires no interpretation layer between telemetry and decision. The rule either matches the data or it does not. When it misfires, we know exactly where to look. We can adjust a threshold, tighten a condition, or add additional context to reduce false positives. The behavior of the system is observable and reproducible.
Agentic systems change everything that we know about this process. Instead of static logic, we allow an agent to interpret telemetry, gather additional evidence, and reason about potential attack hypotheses before producing a verdict.
In simplified terms, the workflow looks like this:
telemetry → agent → investigation → classificationBut under the hood, the process is far more complex. A typical agentic investigation may involve several steps:
- Inspect the telemetry bundle
- Generate possible attack hypotheses
- Retrieve contextual knowledge
- Invoke investigation tools
- Compare observations against prior cases
- Produce a classification and explanation
In other words, the detection process becomes an investigation workflow rather than a simple rule evaluation. Traditionally, human analysts have been extremely effective at this kind of reasoning during the investigation phase that follows a triggered alert. That’s the beauty of the human brain.
Agentic systems attempt to automate parts of that workflow, which introduces a tradeoff of power and risk. The power comes from flexibility. An agent can examine multiple signals, correlate events that no single rule would catch, and incorporate contextual information such as historical behavior or threat intelligence. In essence, the value proposition is to apply human-like “reasoning” (I know LLMs don’t really reason, hence the quotes, but bear with me) to the detection space. Instead of hardcoding every possible attack pattern into a rule engine, we allow a system to synthesize evidence dynamically and arrive at a conclusion.
The risk is the system’s opacity. When a probabilistic model makes a decision, we must determine whether it arrived at that decision for the right reasons. Deterministic detectors misfire in predictable ways. Agentic systems can fail in far more subtle ways in practice, even when the outcome is correct. It may retrieve irrelevant context, straight-up hallucinate shit, or anchor too strongly on a faulty hypothesis. Worse still, it may occasionally reach the correct conclusion through flawed reasoning, masking underlying weaknesses in the system.
Humans were never deterministic in the first place, but many practitioners would argue that trained expertise and reasoning will always outclass a robot in the investigation phase. Reasoning makes for excellent investigation and the tradeoff of determinism for reasoning is sound. This is why applying the pseudo-reasoning of an LLM during the detection phase is a deeply uncomfortable property.
Measuring Detection Engines
Before we can talk about measuring agentic systems, we need to establish the baseline. How do we measure traditional detection systems? This is worth walking through even if you have some familiarity, because the gaps in these metrics are exactly what motivate the rest of this exploration.
Every detection system is ultimately making a bet. When an alert fires, the system is betting that the activity is malicious. When it stays silent, it’s betting the activity is benign. Sometimes those bets are right. Sometimes they’re wrong. We can organize every possible outcome into four buckets:
- True Positive (TP): The system said “malicious” and it was actually malicious. System worked, hacker’s day ruined, case closed, bring in the dancing lobsters.
- False Positive (FP): The system said “malicious” but the activity was actually benign. Your SOC analyst just wasted 20 minutes on nothing.
- True Negative (TN): The system stayed silent and the activity was indeed benign. Good.
- False Negative (FN): The system stayed silent but the activity was actually malicious. An attacker just waltzed right past your detection.
(There’s a subcase of TP/FP where the system detects a benign true positive, but that distinction is not important for this context.)
The measurement of traditional detection mirrors the measurement of machine learning and predictive models, where two of the key metrics are precision and recall.
Precision answers the SOC analyst’s question: when this detection fires, can I trust it? If your detection triggered 100 times last month and 90 of those were real attacks, your precision is 90%. If only 10 were real and the other 90 were noise, your precision is 10% and your analysts are drowning in false positives. The formula is straightforward:
Precision = TP / (TP + FP)Recall answers the CISO’s question: are we actually catching the attacks? If 100 real attacks happened last month and your detection caught 95 of them, your recall is 95%. If it only caught 30, you have a 70% miss rate. That’s the kind of number that keeps people up at night.
Recall = TP / (TP + FN)(Identifying when detection systems has missed something, itself, is a tough problem. Assume we have perfect visibility for the sake of this section.)
Now, here’s the classic detection engineer’s dilemma. You can get perfect recall by alerting on literally everything, but your precision will be garbage. You can get perfect precision by only alerting on the most obvious, slam-dunk cases, but your recall will crater. Practically, this continuum is “exhausted, overworked analysts” on one end and “apocalyptic detection inefficacy” on the other. Every detection system lives somewhere on that tradeoff curve. The F1 score gives us a single number that balances both:
F1 = 2 * (Precision * Recall) / (Precision + Recall)These metrics tell us whether a detection system is doing its job. But notice what they measure: outcomes. They tell us absolutely nothing about why the system reached that answer or how it got there. For a Sigma rule, we don’t care about “how” because we can read the rule and see the logic for ourselves. The “how” is the rule.
For an AI agent, the “how” is a black box full of probabilistic inference. And that’s where things get weird, bruh.
I’m Different Yeah I’m Different (Pull Up To The Scene With Agentic Workflows)
Think about how you’d evaluate a junior analyst. You’d put the whole process on trial. You’d read their investigation notes. Did they check the right logs? Did they consider alternative explanations before jumping to a conclusion? Did they pull the relevant threat intel? Did their reasoning actually support their verdict, or did they get lucky?
Unlike the coolest boss you ever had who was all like “I don’t care how, where, or when the work gets done, just that it gets done” (shoutout to all my Millennial bosses out there), we care deeply about how an AI agent arrived at its conclusion. Every step of the process is rife with landmines. The agent might plan an investigation, pull evidence from a knowledge base, run queries against telemetry, weigh competing hypotheses, and then produce a verdict. If it gets the verdict right but arrived there through flawed reasoning, you have a ticking time bomb. It’ll work until it doesn’t, and you won’t know why it failed.
Evaluating these systems requires measuring the process alongside the outcome because we need to account for all of the failure modes that are not present in traditional rule based detection.
So with that as the context of the problem space, let me show you what that could look like in the technical sense.
Introducing, Azure Eval.
Azure Eval: An Experimental Score Card
Azure Eval is my exploratory proof of concept for what measuring agentic detection systems could look like.
Azure Eval explores this concept of agentic evaluation against the backdrop of Azure identity attacks. I chose this because I’m deeply familiar with, and care about, the subject. The data used in this evaluation itself is fabricated, but that is far less important at this stage than codifying the measurement and evaluation methodology.
Right off the bat, let me knock out a few things:
- This is highly experimental and I don’t know if this methodology is bulletproof.
- This project is about how to measure agents as opposed to how well those agents performed. Right now, I am not concerned with how well the agents are doing at finding evil. This is really just an exploration of what the grading rubric might look like.
So, how does the project actually perform its evaluation? Let’s dive in.
The Trajectory: An Agent’s Case File
When a human analyst investigates an alert, they leave a trail, like writing case notes. An agentic system produces the same kind of trail, just in structured data. The trajectory captures everything the agent did during an investigation, from the plan it formulated, the steps it executed, the tools it called, the evidence it retrieved, and the final classification it produced. Studying this trajectory is the closest thing we have to interviewing the LLM and asking it to show its work.
The harness runs an agent against a benchmark suite of curated security scenarios. For each case, it captures the full trajectory and then scores it across four metric families:
- Classification metrics: did the agent arrive at the correct verdict?
- Planning metrics: did the agent consider the right hypotheses and plan sensible investigation steps?
- Retrieval metrics: did the agent find the right evidence?
- Grounding metrics: is the agent’s reasoning actually supported by the evidence it retrieved?
There’s also an LLM-based judge that evaluates the overall investigation quality, but I’ll cover that separately. Let’s walk through each metric family.
Classification: The Outcome Still Matters
We don’t throw away the traditional metrics. Precision, recall, and F1 still tell us whether the agent is useful in practice. If it consistently misclassifies benign VPN usage as impossible travel, or misses token replay attacks, that’s a dealbreaker regardless of how elegant its reasoning looks.
The harness computes these the same way we discussed earlier: ground truth labels from the benchmark (we know the right answer because we built the scenario), predicted labels from the agent’s final classification, and then the standard precision/recall/F1 calculations.
One wrinkle worth mentioning. Real investigations don’t always end in a clean “malicious” or “benign” verdict. Sometimes the answer is “suspicious but inconclusive.” The harness preserves that nuance. For the core metrics, we collapse to a binary view (“malicious vs. not malicious”), but the full set of verdicts is preserved for deeper analysis.
We also compute something called ROC-AUC when the agent provides a confidence score alongside its classification. The idea here is rather than just checking “did the agent say malicious or benign?”, ROC-AUC measures how well the agent’s confidence scores rank the cases. (It’s the area under the ROC curve—threshold-independent.) Does it assign higher confidence to actual attacks than to benign activity? A perfect ROC-AUC score of 1.0 means the agent always ranks real attacks higher than false alarms. A score of 0.5 means the agent’s confidence scores are no better than a coin flip. It’s a useful measure of whether the agent “knows what it knows.”
Planning: Did the Agent Think Before Acting?
Here’s something that might not be obvious if you haven’t worked with agentic systems: these things can fail before they ever touch a tool. The agent starts by formulating a plan, which is the set of hypotheses it wants to test and the investigation steps it intends to execute. We measure planning quality against a grading rubric embedded in each benchmark case. It’s basically an answer key, but for the investigation process rather than the final answer.
For each case, the rubric defines:
- Expected hypotheses: the reasonable explanations a thorough investigator should consider. For a suspicious login from two distant locations, this might include “impossible travel,” “token theft,” and “VPN usage.”
- Expected steps: the investigation actions a competent analyst would take. For that same case: “check login history,” “calculate geographic distance,” “verify MFA status.”
- Correct hypothesis: the one that actually explains the scenario.
From these, the harness computes four scores:
- Hypothesis recall: Out of all the hypotheses a good investigator should consider, how many did the agent actually include in its plan? If the rubric expects three hypotheses and the agent only considered one, that’s a recall of 33%.
- Correct hypothesis present: did the agent even consider the right explanation? This is a binary check. If an impossible travel case is actually caused by token theft and the agent never put “token theft” on its list of possibilities, that’s a problem regardless of what else it considered.
- Step coverage: out of all the expected investigation steps, how many did the agent’s plan include? If the rubric says to check login history, calculate distance, and verify MFA, and the agent only planned to check login history, that’s 33% step coverage.
- Step efficiency: a penalty for plans that are excessively long. If the rubric expects 5 steps and the agent planned 15, that bloat wastes resources and suggests the agent doesn’t know what’s important. We penalize plans longer than twice the expected step count.
Retrieval: Did the Agent Find the Right Evidence?
Many agentic systems have access to runtime knowledge base information via RAG (Retrieval-Augmented Generation). At runtime, the agent can collect additional information from an offboard source and integrate that information into its process. An agent investigating an impossible travel alert might need to pull a document on known VPN exit node IP ranges or maybe even a SOC runbook. If the agent has access to that knowledge base but fails to surface the right documents, it’s operating on incomplete information. We have to assume RAG use so we can better model the evaluation, given its wide adoption in agentic systems.
Each benchmark case can specify which documents from the knowledge base are relevant to the investigation. The harness then tracks what the agent actually retrieved and computes metrics based on retrieval, using what I like to call the “at-k’s”:
- Recall@k: “Of the documents that should have been retrieved, how many did the agent actually find?” We measure this at different depths: the top 3 results (k=3), top 5 (k=5), and top 10 (k=10). The “k” just means “look at the first k results.” If there are 4 relevant documents and the agent’s top 5 results include 3 of them, that’s a recall@5 of 75%.
- Precision@k: The flip side: “Of the documents the agent retrieved, how many were actually relevant?” If the agent pulled 5 documents but only 2 were useful, that’s a precision@5 of 40%.
- nDCG@k (Normalized Discounted Cumulative Gain): nDCG measures ranking quality by rewarding putting the most relevant documents at the top of the list. The math here is far less intimidating than the name suggests. This one rewards the agent for putting the most relevant documents at the top of its results, not buried at position 9 out of 10. If there are two relevant documents and the agent retrieved both, but one was at position 1 and the other was at position 8, that’s worse than having both in the top 3. An analyst who finds the key evidence on the first search is more effective than one who stumbles onto it after extensive digging.
For this experiment, the RAG is equipped with a simple set of documents detailing some notional threat intel for common Azure attack scenarios. This is a representative sample and you can imagine that this stands in place of a larger retrieval system equipped with tons of documents.
Grounding: Is the Reasoning Supported by Evidence?
The core discomfort of the whole thought experiment of applying LLMs to detection is that they have a well-documented tendency to make shit up. In a security context, this is especially dangerous and I hope I don’t have to explain why.
The grounding metrics measure whether the agent’s reasoning is actually tethered to the evidence it retrieved. We check three things:
- Evidence utilization: the agent retrieved documents during its investigation. Did it actually use them? If the agent pulled 5 documents but only referenced information from 1 of them in its reasoning, something is off. Either the agent retrieved irrelevant material or it’s ignoring the evidence it found.
- Citation correctness: each benchmark rubric can specify key facts that should appear in the agent’s reasoning. For an impossible travel case, the rubric might expect the agent to mention “geographic distance” and “4 minutes” in its explanation. Citation correctness measures whether those key facts actually show up.
- Unsupported claim rate: for each sentence in the agent’s reasoning, we check whether it has any basis in the retrieved evidence. A sentence like “the user’s account shows signs of credential stuffing” is fine if the agent retrieved evidence of repeated failed logins. It’s not fine if the agent pulled nothing of the sort and fabricated the claim. The unsupported claim rate is the fraction of the agent’s reasoning that has no connection to any evidence it actually retrieved.
A low evidence utilization score suggests the agent is reasoning from vibes rather than evidence. A high unsupported claim rate means it’s making things up. These metrics exist because “the agent got the right answer” doesn’t matter if the reasoning is built on hallucinated foundations.
Benchmark Cases: Building the Test Scenarios
Garbage in, garbage out! None of these metrics mean anything without good test data. You need scenarios where you know the right answer, the right investigative process, and the right evidence, so you can measure where the agent succeeds and where it fails. This is where security domain expertise comes into play.
For the example test suite, I build a series of common realistic-ish Azure scenarios where the telemetry indicates either outright malice, common false positive attributes, or some ambiguous thing in between. The test suite includes logins that have the impossible travel attributes, OAuth consent to an application, inbox rule manipulation, and other Azure attack stuff.
Each test suite consists of the following:
- Telemetry events: Azure sign-in logs, audit events, or service principal activity. These are the raw signals the agent has to work with. This project uses some poetic license with the realism of the logs but they are generally realistic.
- Task instructions: What the agent is asked to investigate. “Analyze these sign-in events and determine whether malicious activity occurred.”
- Expected outcomes: The ground truth. We know whether this scenario represents an attack or benign activity because we designed it that way.
- The grading rubric: The answer key for the process. Expected hypotheses, expected investigation steps, which knowledge base documents the agent should have retrieved, and what key facts should appear in its reasoning.
> [NOTE] Note that the real nitty gritty of the test suite details are, for this project's purpose, not super important. Getting the general gist of the Azure attack scenarios down is fine for right now given that we are not concerned with how the models actually perform, but rather how to even measure that performance in the first place. If you were to run this to actually evaluate model performance, extremely precise test suite detail is non-negotiable.The Trajectory Judge: Grading the Investigation
The classification, planning, retrieval, and grounding metrics I described above are all computed programmatically. But some aspects of investigation quality are tough to nail down with computation. Did the agent investigate all the relevant angles, or did it tunnel-vision on one hypothesis? Was the investigation plan logical and well-ordered, or did it jump around chaotically? Did the agent use its tools effectively, or did it run the same query three times? These are the kind of judgment calls that a senior analyst could evaluate by reading the case file, but hard to reduce to programmatic logic.
To measure that dimension of performance, we use an LLM judge, which is a separate AI model whose only job is to read the agent’s trajectory and grade the investigation quality. The judge analyzes the entire model process to make the determination. It also gets the benchmark context so it knows what a good investigation should look like.
The judge scores the trajectory on a 1-to-5 scale across five dimensions:
- Completeness: Did the agent investigate all the relevant aspects, or did it leave obvious stones unturned?
- Plan Quality: was the investigation plan logical and well-ordered? Did the steps build on each other sensibly?
- Tool Use: Did the agent pick the right tools for the job and use them effectively?
- Grounding: Are the agent’s conclusions supported by the evidence it actually found?
- Reasoning Consistency: Does the agent’s logic hold together? Does its conclusion follow from its observations?
The judge also tags specific failure modes: “missed critical step,” “hallucinated evidence,” “conclusion contradicts observations.” These tags are useful for identifying patterns of failure across many cases.
I know what you’re thinking. “Quis custodiet ipsos custodes? Who watches the watchmen?” Using an AI to grade an AI is circular. It’s a fair concern. But the judge isn’t doing security analysis. It’s reading an investigation transcript and grading it against explicit criteria, so it’s more like a rubric-based exam than an open-ended assessment. The judge’s scores are one signal among many. The programmatic metrics (precision, recall, step coverage, unsupported claim rate) remain the backbone of the evaluation. The judge fills in the gaps where mechanical checks fall short.
Additionally, we have the ability to test the judges efficacy by removing it completely from the test harness, which is a great segue into…
Ablation Studies: Trust No Thing
Ablations are the systematic removal of components of the test harness to prove that each one has a material affect on the outcome. Ablations strip components out of the system one at a time, then measure how the removal affects the entire process. In our case, we run the same benchmark suite with a few configurations that ablate specific elements of the test suite:
- Baseline: No knowledge base, no investigation tools, no multi-step reasoning. Just hand the agent the raw telemetry and ask “is this malicious?” This is the simplest possible approach with classify from telemetry alone.
- No retrieval: The full agent with planning and tools, but no access to the knowledge base. This tells us whether the knowledge base actually helps or whether the agent can figure things out from the telemetry and tools alone. Takes RAG out of the equation.
- No tools: The full agent with planning and knowledge base access, but no investigation tools. This tells us whether tool use (querying logs, checking IP reputation, etc.) adds real value.
- Full agent: Everything enabled. Planning, knowledge base, tools, the works.
Putting It Together
The harness produces an evaluation scorecard for each benchmark suite run. That scorecard consolidates everything:
- Classification metrics: Precision, recall, F1, and ROC-AUC. Did the agent get the answers right?
- Planning metrics: Hypothesis recall, step coverage, step efficiency. Did the agent investigate properly?
- Retrieval metrics: Recall@k, precision@k, nDCG@k. Did the agent find the right evidence?
- Grounding metrics: Evidence utilization, citation correctness, unsupported claim rate. Is the agent’s reasoning tethered to reality?
- Trajectory grades: The LLM judge’s scores for investigation quality, per-case and averaged across the suite.
The project logs everything to a results directory with the option to run in debug mode for full visibility into each step in the process. Without that visibility, you’re back to “the agent got it wrong and we don’t know why,” which is the exact problem we set out to solve.
Example: signin_001 (Impossible Travel)
So… with all of that out of the way, how does this thing even work? Let’s fire it up against one test suite.
For this test, I’m using the OpenCode Minimax M2.5 model. Obviously, LLM selection is, itself, a key component of performance. But I don’t so much care about the agent performance itself right now, so any model will do for an end-to-end test.
After setting the API key in the .env file, I fire up the test:
λ uv run azure-eval run --suite signin_suite --max-cases 1 --ablation --output results/This loads signin_001, a medium difficulty test that consists of two sign-in logs that have the attribute of impossible travel. The user signs in from New York at 09:00 UTC and Tokyo at 09:04 UTC, ~10,800 km apart in four minutes. Ground truth is malicious (impossible travel / token replay).
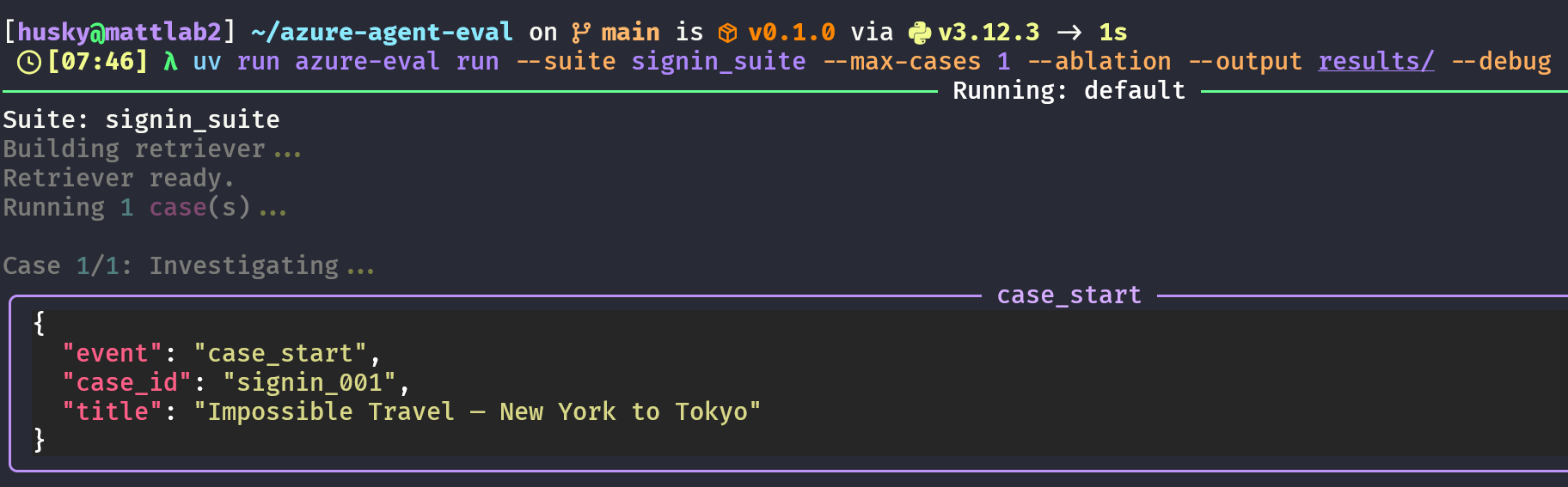
In debug mode, we can see the agent plan how to handle this scenario:
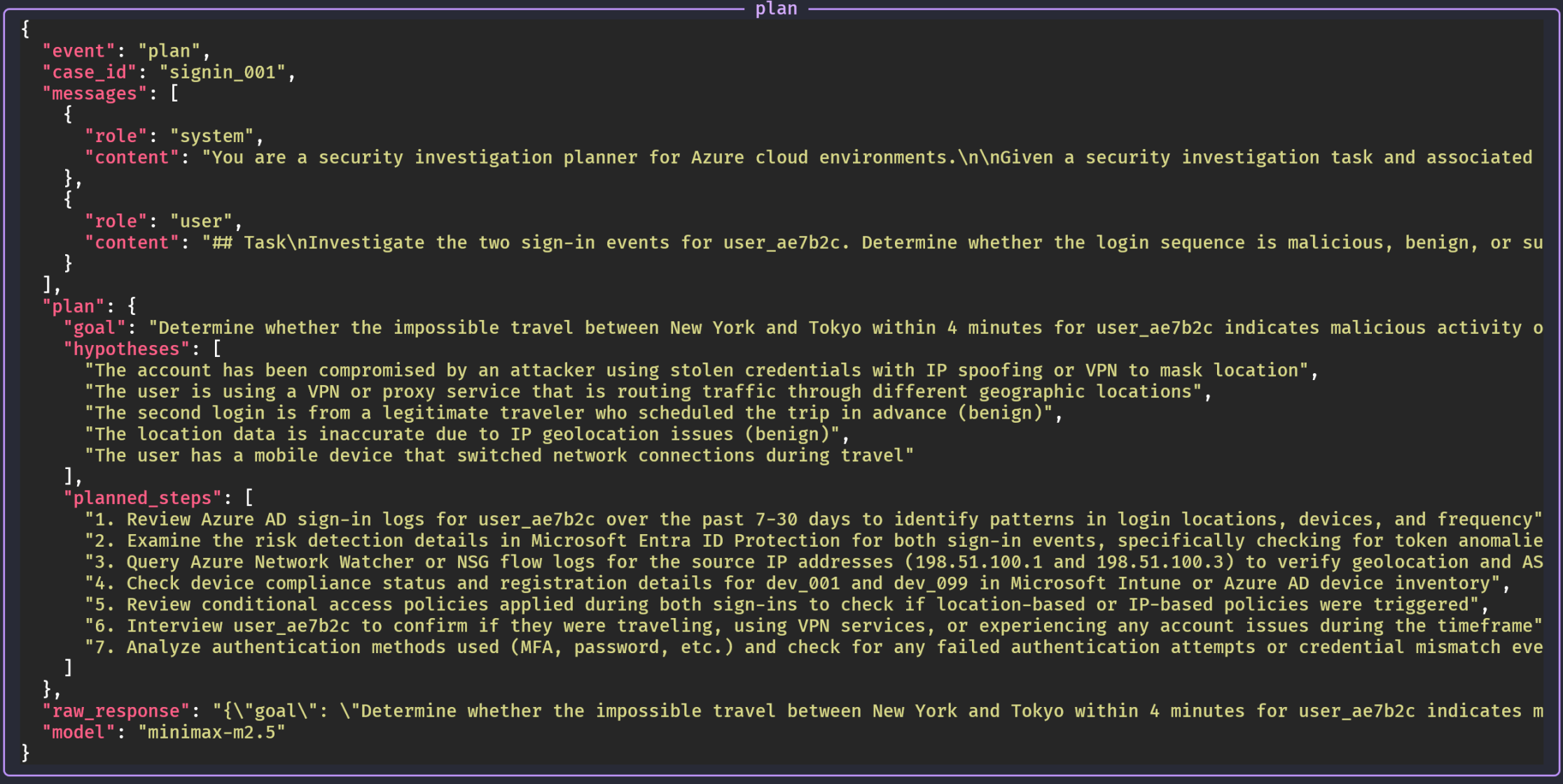
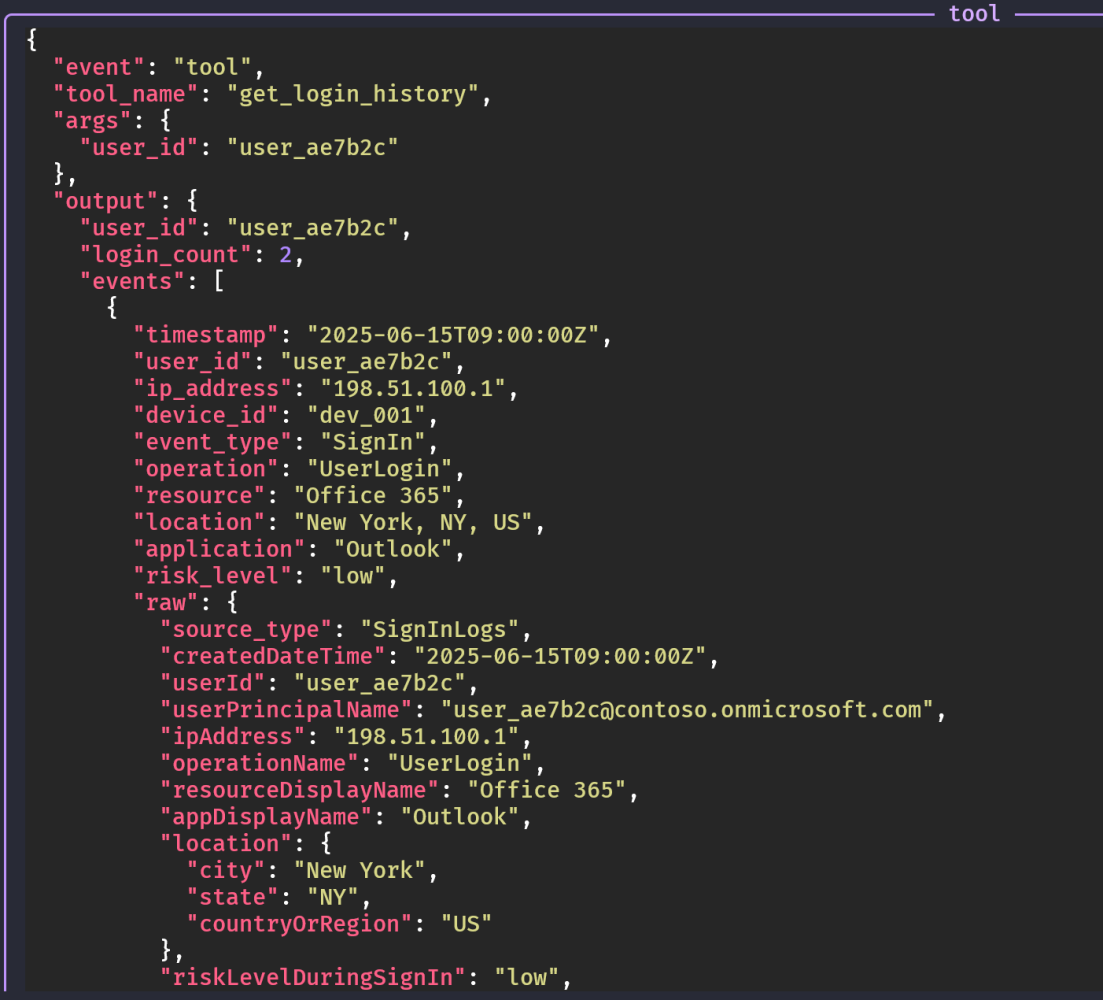
Step 1: the tool to use. The agent called geo_distance_tool with the two IPs. We see the agent collecting and analyzing the telemetry:
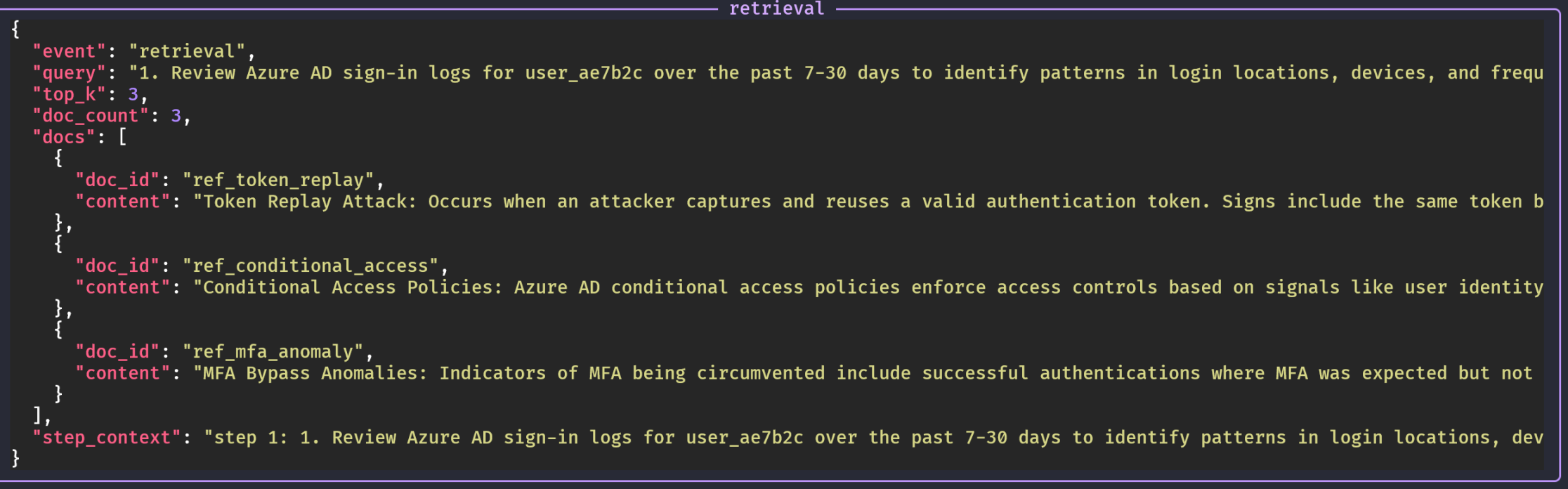
The agent uses RAG to source documents from the knowledge base:
…and so on. Each step is documented in the debug log, so we can see the process chain for the investigation.
Finally, the agent makes the final classification. Through its investigation, it rendered this scenario suspicious, not outright malicious:
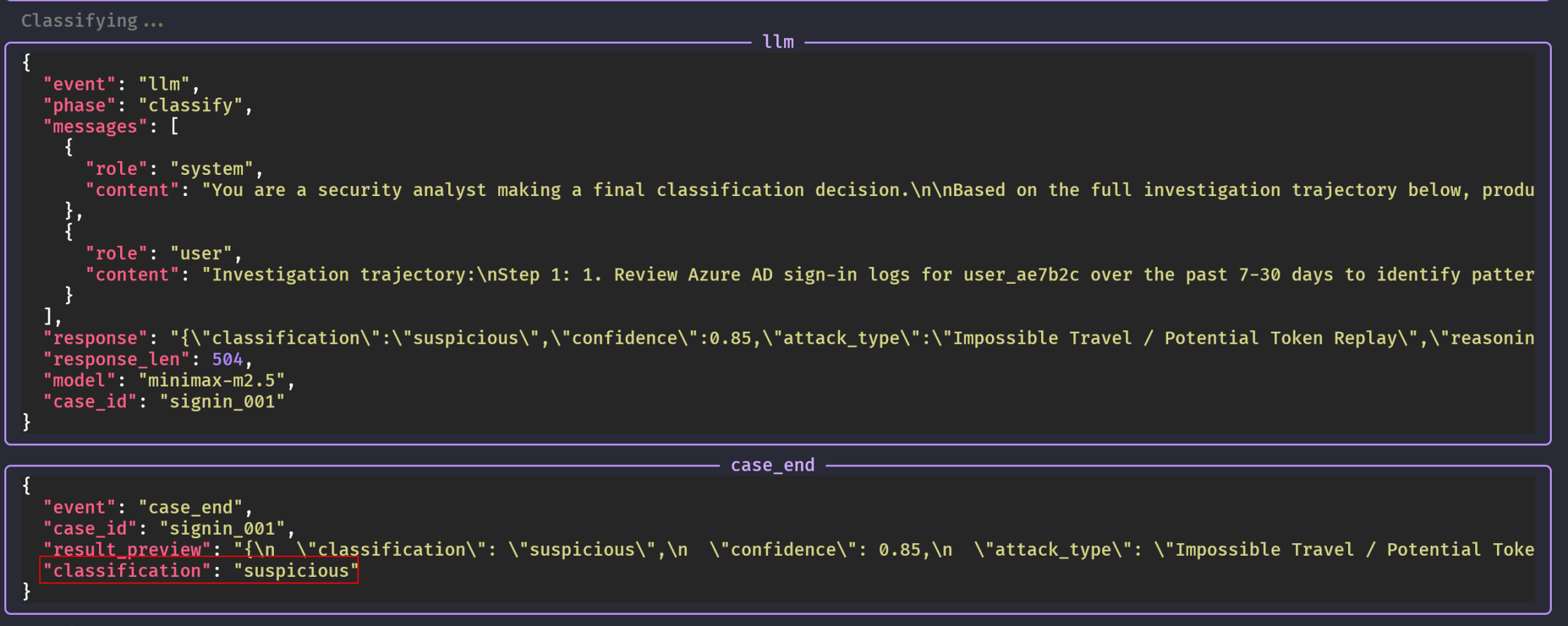
We see the agent’s score in the scorecard:
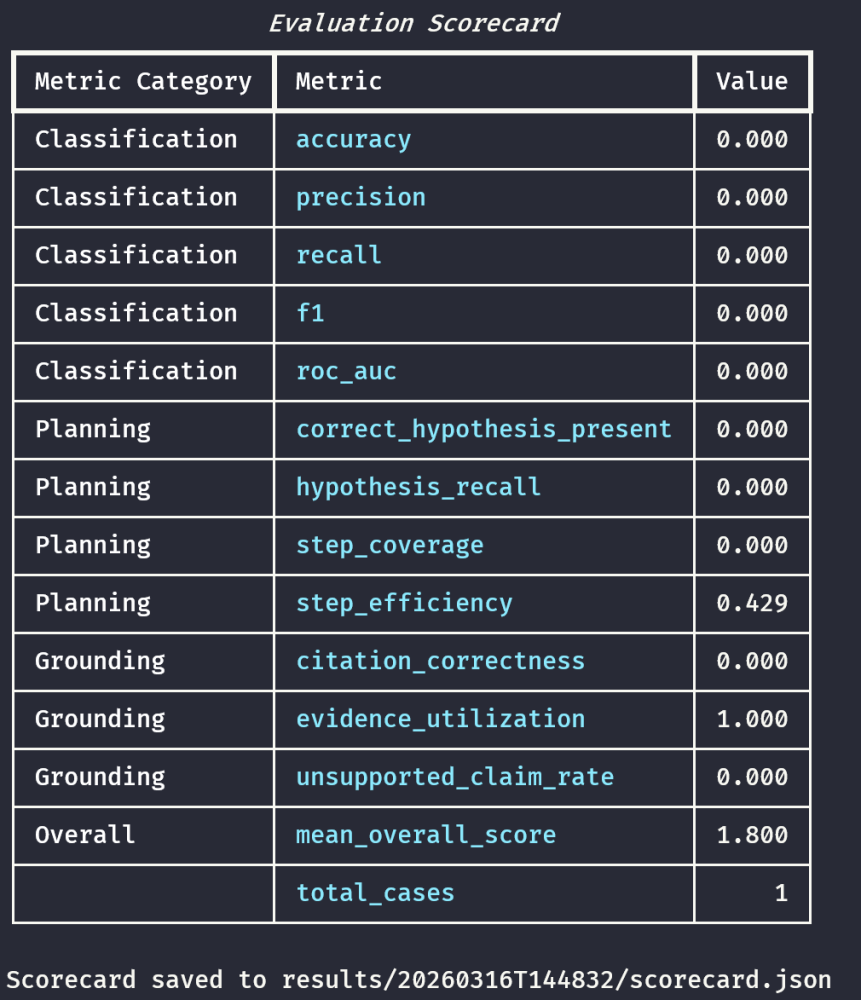
There is only one test in this case, but multiple tests are represented in the scorecard. In a full run with many cases, the scorecard aggregates over the whole suite. The precision, recall, F1, ROC-AUC, and subsequent planning metrics will reflect the entire suite of tests.
After the initial round of evaluation, the ablation tests run to remove each component in sequence and measure the results. Once those results are in, we can interpret the entire test.
Results
In this example of the test, during the initial pass, the agent classified the case as suspicious with confidence 0.85 and attack type “Impossible Travel / Potential Token Replay.” So the classification was wrong for the binary malicious-vs-not benchmark (precision/recall/F1 and accuracy all 0.0 on that one case). The scorecard shows step efficiency 0.43, hypothesis recall 0, and the trajectory grader gave an overall score of 1.8 with failure tags including incomplete_investigation, tools_not_executed, ip_geolocation_not_verified, and repetitive_tool_calls. The judge’s rationale from the run:
“The investigation is severely incomplete - only 2 of 7 planned steps were executed. Steps 3-6 all show ‘tool=none’ indicating no tools were invoked. The agent repeated the same get_login_history call twice instead of using different tools. Critical verification steps (IP geolocation, device compliance, conditional access policies, user interview) were skipped. While the final classification of ‘suspicious’ aligns with the benchmark, the reasoning is not well-grounded…”
So the agent never called geo_distance_tool in that first run, and the grader correctly flags missing evidence and weak grounding.
I’ll be noting this in the model’s quarterly SOC analyst performance review.
Ablation results
Next, the ablation results! The harness re-ran signin_001 under four configurations and wrote scorecards under full/, no_tools/, no_retrieval/, and baseline/. Here’s what the run shows.
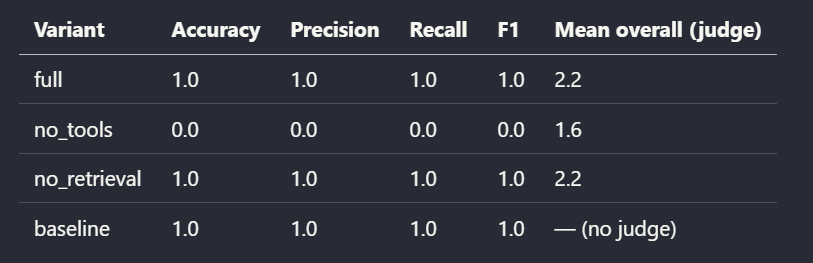
For signin_001 (impossible travel, one case), the ablation run shows that removing tools removed the ability to both gather the right evidence and classify correctly, while removing retrieval did not hurt accuracy but did hurt the judged quality of reasoning (grounding, handling of tool failures).
From here, analyzing the written scorecards and judge rationales are exactly what you’d use to iterate. The results tell you to add or refine tools, refine prompts, swap models, or any other system tuning steps.
Conclusion
Is it a good idea to use LLMs for detection and response? I have no idea. There’s no clear consensus in the literature. The industry doesn’t really seem to know yet and I think it will be a minute until we have a clear answer.
But in the mean time, is it a good idea to think about how we would measure those agentic detection systems if (well, when) they appear? Absolutely. Evaluation means applying scientific rigor to the premise, which is always a good idea.
Measure twice, analysts.
References
- Berger, Y. Taming LLMs to Detect Anomalies in Cloud Audit Logs. YouTube. https://www.youtube.com/watch?v=b-MF3yGk3zQ
- Fawcett, T. An introduction to ROC analysis. Pattern Recognition Letters 27(8), 861–874 (2006). https://doi.org/10.1016/j.patrec.2005.10.010
- Järvelin, K. & Kekäläinen, J. Cumulated gain-based evaluation of IR techniques. ACM SIGIR (2000). https://dl.acm.org/doi/10.1145/582415.582418
- Lewis, P. et al. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. NeurIPS (2020). https://arxiv.org/abs/2005.11401
- Powers, D. M. W. Evaluation: from precision, recall and F-measure to ROC, informedness, markedness and correlation. International Journal of Machine Learning Technology 2(1), 37–63 (2011). https://arxiv.org/abs/2010.16061
- Understanding how AI agent trajectories guide agent evaluation. objectways.com. https://objectways.com/blog/understanding-how-ai-agent-trajectories-guide-agent-evaluation/
- Wu, Y. et al. ExCyTIn-Bench: Evaluating LLM agents on Cyber Threat Investigation. arXiv preprint (2025). https://arxiv.org/abs/2507.14201